概述 之前文章讲了HashMap。HashMap是一种非常常见、非常有用的集合,但在多线程情况下使用不当会有线程安全问题。
大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序 ,也就是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序 。该迭代顺序可以是插入顺序或者是访问顺序。
我们写一个简单的LinkedHashMap的程序演示一下:
1 2 3 4 5 6 7 8 9 10 11 12 LinkedHashMap<string, integer="" > lmap = new LinkedHashMap<string, integer="" >();"语文" , 1 );"数学" , 2 );"英语" , 3 );"历史" , 4 );"政治" , 5 );"地理" , 6 );"生物" , 7 );"化学" , 8 );for (Entry<string, integer="" > entry : lmap.entrySet()) {": " + entry.getValue());
运行结果是:
1 语文: 1 数学: 2 英语: 3 历史: 4 政治: 5 地理: 6 生物: 7 化学: 8
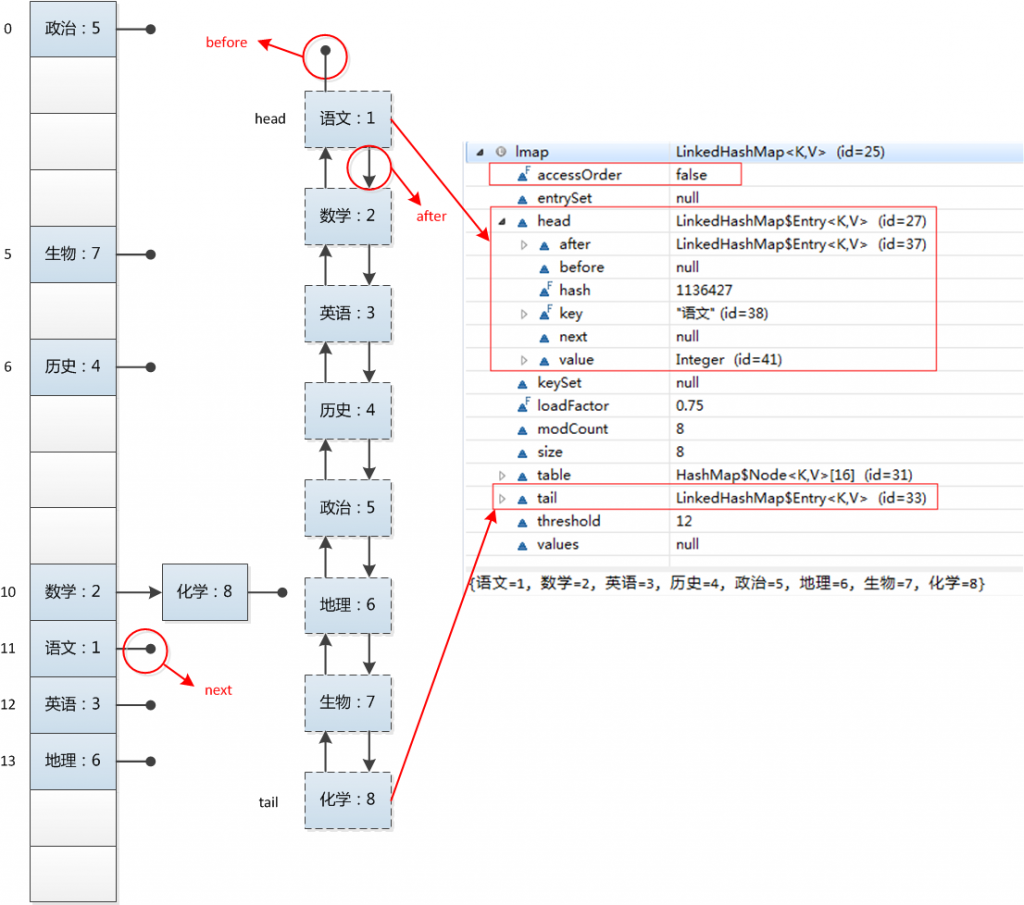
我们可以观察到,和HashMap的运行结果不同,LinkedHashMap的迭代输出的结果保持了插入顺序。是什么样的结构使得LinkedHashMap具有如此特性呢?我们还是一样的看看LinkedHashMap的内部结构,对它有一个感性的认识:
可以看到LinkedHashMap内部结构其实跟HashMap是一样的,只不过比HashMap多了一个双向链表。
四个关注点
关 注 点 结 论
LinkedHashMap是否允许空
Key和Value都允许空
LinkedHashMap是否允许重复数据
Key重复会覆盖、Value允许重复
LinkedHashMap是否有序
有序
LinkedHashMap是否线程安全
非线程安全
LinkedHashMap基本结构 LinkedHashMap可以认为是HashMap+LinkedList ,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
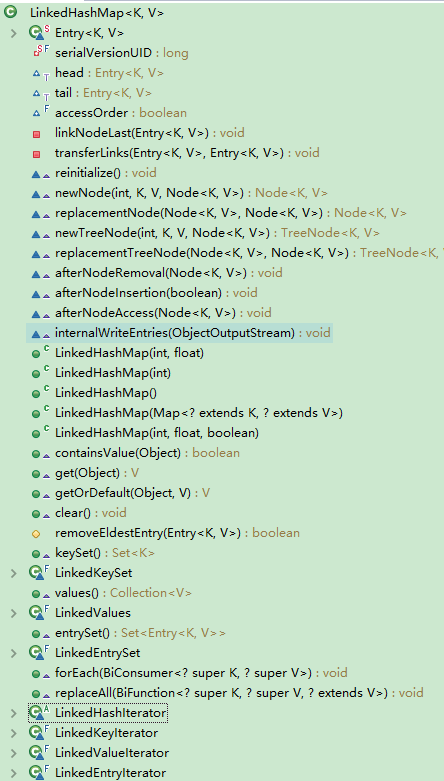
其实LinkedHashMap本身就继承自HashMap,也就是说它继承了HashMap中所有的非私有方法和属性:
重点属性和方法 我们可以看到LinkedHashMap中有几个特有的属性和方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;final boolean accessOrder;void afterNodeAccess (Node<K,V> p) void afterNodeInsertion (boolean evict) void afterNodeRemoval (Node<K,V> p)
三个属性中,accessOrder表示是以访问排序还是以插入排序。
head和tail表示双链表的头结点和尾结点,用来表示循环双向链表的入口和出口。它们都是LinkedHashMap.Entry,我们看看这个Entry和HashMap中的Entry(Node)有何不同:
1 2 3 4 5 6 static class Entry <K ,V > extends HashMap .Node <K ,V > int hash, K key, V value, Node<K,V> next) {super (hash, key, value, next);
可以看到Entry继承自HashMap.Node,它具有的完整属性如下所示:
1 2 3 4 5 6 7 8 9 10 final int hash;final K key;
构造方法 LinkedHashMap中定义五个构造方法,都是交给父类HashMap来初始化的,不过都初始化了accessOrder为false,也就是说默认是按照插入顺序来排序的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public LinkedHashMap (int initialCapacity, float loadFactor) super (initialCapacity, loadFactor);false ;public LinkedHashMap (int initialCapacity) super (initialCapacity);false ;public LinkedHashMap () super ();false ;public LinkedHashMap (Map<? extends K, ? extends V> m) super ();false ;false );public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder) super (initialCapacity, loadFactor);this .accessOrder = accessOrder;
三个重点函数分析 上面我们提到了HashMap中定义下三个空实现的方法:
1 2 3 4 void afterNodeAccess (Node<K,V> p) void afterNodeInsertion (boolean evict) void afterNodeRemoval (Node<K,V> p)
LinkedHashMap继承于HashMap,重新实现了这3个函数,通过函数名我们知道这三个函数的作用分别是:节点访问后、节点插入后、节点移除后做一些事情。
afterNodeAccess() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void afterNodeAccess (Node<K,V> e) if (accessOrder && (last = tail) != e) {null ;if (b == null )else if (a != null )else if (last == null )else {
就是说在进行get和put之后就算是对节点的访问了,那么这个时候就会更新链表,把最近访问的放到最后,保证链表。
LinkedHashMap重写了get方法但使用的是HashMap的put方法,get方法源码如下:
1 2 3 4 5 6 7 8 public V get (Object key) if ((e = getNode(hash(key), key)) == null )return null ;if (accessOrder)return e.value;
可以看到确实调用了afterNodeAccess()方法调整链表相对位置。
再来看看HashMap中的put方法有没有调用afterNodeAccess:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) if (e != null ) { if (!onlyIfAbsent || oldValue == null )return oldValue;if (++size > threshold)return null ;
我们发现HashMap中的put方法调用了afterNodeAccess方法同时也调用了afterNodeInsertion()方法。
afterNodeInsertion() 1 2 3 4 5 6 7 void afterNodeInsertion (boolean evict) if (evict && (first = head) != null && removeEldestEntry(first)) {null , false , true );
afterNodeInsertion()方法表示的是在put操作之后需要进行的操作,如果用户定义了removeEldestEntry的规则,那么就可以执行相应的移除操作。
removeEldestEntry()方法在LinkedHashMap中默认实现是false,主要是交给用户去实现,以达到自动删除头结点(也就是访问最少结点,也叫eldest)的效果,这也是LinkedHashMap常用来作缓存的原因。
afterNodeRemoval() 1 2 3 4 5 6 7 8 9 10 11 12 13 void afterNodeRemoval (Node<K,V> e) null ;if (b == null )else if (a == null )else
这个函数是在移除节点后调用的,就是将节点从双向链表中删除。
我们从上面3个函数看出来,基本上都是为了保证双向链表中的节点次序或者双向链表容量 所做的一些额外的事情,目的就是保持双向链表中节点的顺序要从eldest到youngest。
LinkedHashMap实现LRU算法缓存 LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class LRUCache extends LinkedHashMap public LRUCache (int maxSize) {super (maxSize, 0.75F , true );protected boolean removeEldestEntry (java.util.Map.Entry eldest) {return size() > maxElements;private static final long serialVersionUID = 1L ;protected int maxElements;
顾名思义,LRUCache就是基于LRU算法的Cache,这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。
LinkedHashMap可以实现LRU算法的缓存基于两点:
1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致
2、LinkedList提供了一个boolean值和一个方法可以让用户指定是否实现LRU
第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。
“访问”,这个词有两层意思:
1、根据Key拿到Value,也就是get方法
2、修改Key对应的Value,也就是put方法
我们上面已经看过get和put方法的源码了,主要涉及afterNodeAccess和afterNodeInsertion两个方法,前者将链表的结点以访问的频繁度排列,后者通过自定义的removeEldestEntry规则实现何时清理缓存。
参考 JDK1.8 LinkedHashMap源码
Java集合之LinkedHashMap