深入理解Kotlin协程(五)——官方框架
协程框架概述
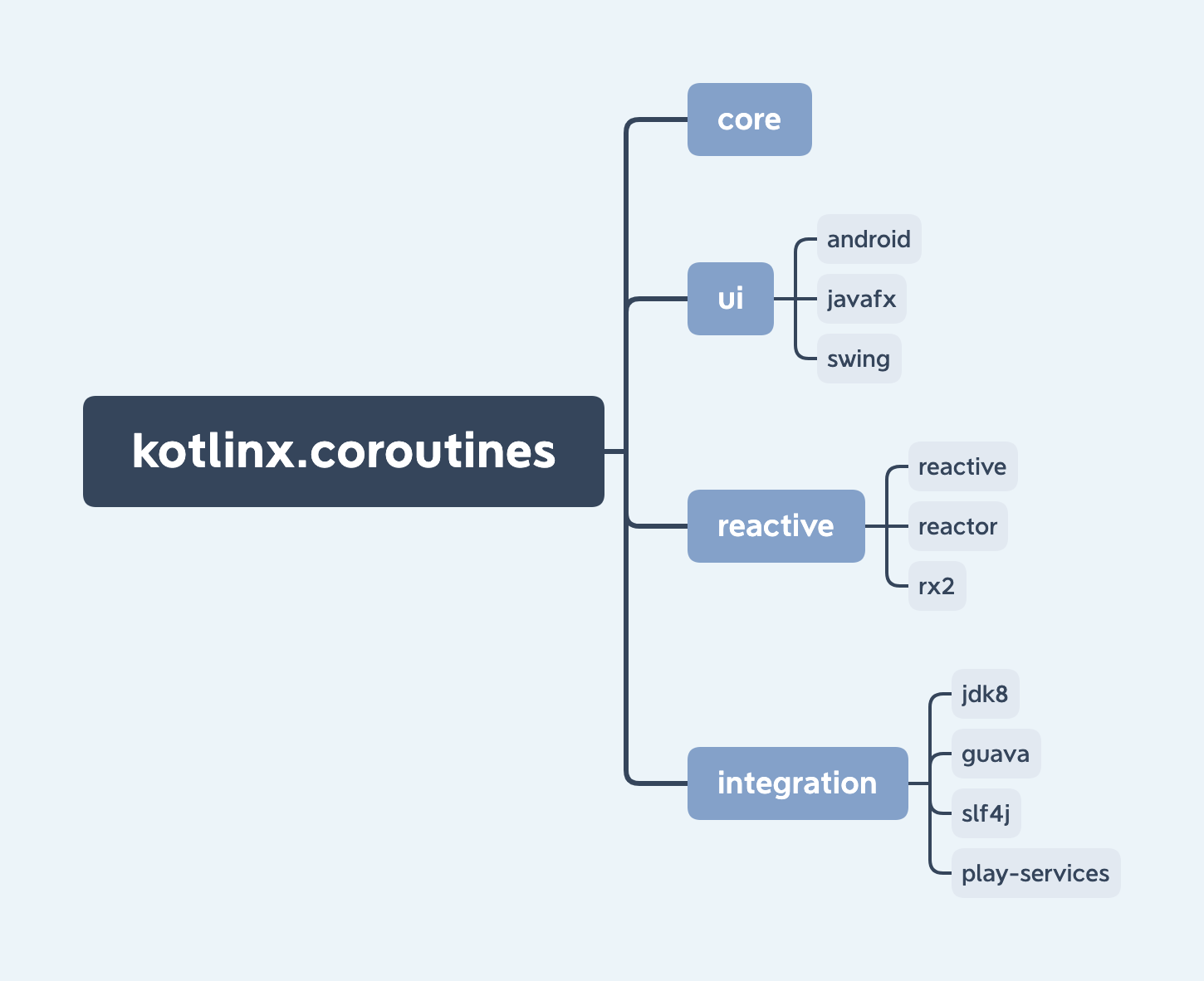
Kotlin协程的官方框架kotlin.coroutines是一套独立于标准库之外的以生产为目的的框架,框架本身提供了丰富的API来支撑生产环境中异步程序的设计和实现。主要包含以下几个部分:
- core:框架的核心逻辑,包含前两篇文章实现的内容和Channel、Flow等特性。
- ui:包含android、javafx、swing三个库,用于提供各平台的UI调度器和一些特有的逻辑。
- reactive:提供对各种响应式编程框架的协程支持。
- reactive:提供对Reactive Streams的协程支持。
- reactor:提供对Reactor的协程支持。
- rx2:提供对RxJava 2.x版本的协程支持。
- integration:提供与其他框架的异步回调的集成。
- jdk8:提供对CompletableFuture的协程API的支持。
- guava:提供对ListenableFuture的协程API的支持。
- slf4j:提供MDCContext作为协程上下文的元素。
- play-services:提供对Google Play服务中的Task的协程API的支持。
启动模式
kotlin官方协程框架中协程的启动多了一个start参数:
1 | |
启动模式总共有4种。
- DEFAULT :协程创建后,立即开始调度,在调度前如果被取消则进入取消相应的状态。
- ATOMIC:协程创建后,立即开始调度,协程执行到第一个挂起点前不响应取消。
- LAZY:只有协程主调调用start、join或者await等函数时才会开始调度,如果调度前被取消将进入异常结束状态。
- UNDISPATCHED:协程创建后立即在当前函数调用栈中执行,直到遇到第一个挂起点。
调度器
官方框架中预置了4个调度器,我们可以通过Dispatchers对象访问它们。
- Default:默认调度器,适合处理后台计算,是一个CPU密集型任务调度器。
- IO:IO调度器,适合执行IO相关操作,是一个IO密集型任务调度器。
- Main:UI调度器,根据平台不同会被初始化为对应的UI线程的调度器,例如ANdroid平台的主线程(UI线程)。
- Unconfined:未定调度器,不要求协程执行在特定的线程上。如果协程的调度器是Unconfined,那么它在挂起点恢复执行时后续代码会在恢复所在的线程上直接执行。
如果内置的调度器无法满足需求,也可以自定义调度器,只需要实现CoroutineDispatcher接口即可,如下所示。
1 | |
更多的时候我们将自己定义好的线程池转成调度器。
1 | |
这里用到了asCoroutineDispatcher和withContext两个扩展函数。asCoroutineDispatcher实际上也就是把线程池转为CoroutineDispatcher接口的实现,withContext函数会将参数中的Lambda表达式调度到对应的调度器上,返回值为Lambda表达式的值,它的作用等价于async{ … }.await(),且内存开销更低,因此对于async之后立即await的情况都可以用withContext来提高性能。
全局异常处理器
官方框架中支持全局的异常处理器,在根协程(顶级协程)未设置异常处理器时,未捕获异常会优先传递给全局异常处理器处理,之后再交给线程的UncaughtExceptionHandler。
定义一个全局异常处理器与普通的异常处理器没有区别:
1 | |
关键在于我们需要在classpath目录下创建META-INF/services目录,在其中创建一个名为kotlinx.coroutines.CoroutineExceptionHandler的文件,文件的内容是全局异常处理器的全类名。
取消检查
协程中挂起函数可以通过suspendCancellableCoroutine来响应所在协程的取消转台,那么没有挂起点的话如何取消呢?例如下面的代码:
1 | |
我们可以效仿线程的取消,在while循环内设置一个状态监听,这里我们可以监听父协程的存活状态来判断是否取消。
1 | |
实际上这里还有更简便的方法,那就是yield函数。yield函数内部会调用CoroutineContext#checkCompletion函数来检查协程是否存活:
1 | |
这点与线程的yield函数不同,线程的yield函数仅让出线程的执行权,并不会进行中断状态检查。
超时取消
官方提供了两个api用于超时取消。
1 | |
禁止取消
官方框架提供一个名为NonCancellable的上下文实现用于禁止作用范围内的协程被取消。
1 | |
热数据通道Channel
Channel用于连接协程实现协程间的通信,它实际上就是一个并发安全的队列,用法如下。
1 | |
这里使用channel实现了一个简单的生产消费者模式,producer中每隔1s向Channel发送一个数字,而consumer一直在读取Channel来读取这个数字并打印。channel.receive必然是挂起的,那么channel.send一定是个挂起函数吗?
Channel的容量
前面说了channel本质是个队列,那么队列是有空间的,一但空间不足就可能会出现两种情况,阻塞或者直接抛异常。send在发送消息时,队列的缓冲区也可能会满,满了之后send就需要挂起协程等待外部调用receive取走元素了。来看下Channel缓冲区的定义。
1 | |
根据传入的容量值不同,这里创建了四种不同的Channel:
- RendezvousChannel:缓冲区大小为0或者说没有缓冲区的Channel。这意味着send调用后会马上挂起直到receive被调用,receive调用后也会马上挂起协程直到另一个协程调用send。
- LinkedListChannel:缓冲区是一个的LinkedList,它的send永远不会挂起协程,同时offer总是返回true,这意味着它“来者不拒”,这点跟LinkedBlockingQueue有点类似。
- ConflatedChannel:缓冲区仅保留最近send过来的一个元素。send函数不会挂起协程,但仅保留最近的send的一个元素,这意味这如果receive调用时机晚了会丢失早先send的数据。
- ArrayChannel:接收一个值作为缓冲区大小,效果类似于ArrayBlockingQueue,缓冲区满了Sender挂起,缓冲区空了Receiver挂起。
迭代Channel
Channel重写的Iterator操作符,因此可以进行迭代。
1 | |
produce和actor
可以使用produce或者actor快速构建一个生产者或者消费者协程。
1 | |
ReceiveChannel和SendChannel是Channel的父接口,分别定义了receive和send方法。produce构造除了ProducerCoroutine对象,该类是Job的实现类之一,主要工作是在协程结束或被取消时关闭Channel,send同理。
1 | |
Channel的关闭
Channel存在关闭的概念,所以被称为热数据流。当我们调用Channel的close方法时,它会立即停止接收元素,这个时候它的isClosedForSend会立即返回true,该属性表示发送端已经关闭。当Channel缓冲区的所有元素都被读取后,isClosedForReceive会返回true,表示接收端也已经关闭。
跟I/O流一样,我们需要在合适的时候关闭Channel,如果不关闭则会导致接收端一直处于挂起等待状态。对于单向通信的Channel,由发送端处理关闭较为合适;对于双向通信的Channel则协商关闭。
BroadcastChannel
前面的Channel发送端和接收端可能存在一对多的情况,不过同一元素只会被一个接收端接收到。不过BroadcastChannel中多个接收者不存在互斥行为。可以通过BroadcastChannel方法来构建一个BroadcastChannel对象,再通过这个对象来获取ReceiveChannel。
1 | |
或者可以使用普通的channel转换:
1 | |
Channel.broadcast方法实际就是读取原Channel的元素然后再通过广播发送。
1 | |
有一点需要注意的是,由于这里读取了原Channel,所以如果有其他协程也在读取这个Channel,可能会存在互斥的情况。
Channel的内部结构
支持Channel胜任并发场景的是其内部数据结构。本节来探讨缓冲区是链表和数组的版本。链表版本的定义主要是在AbstractSendChannel中。
1 | |
LockFreeLinkedListHead本身是一个双向链表的节点,Channel把它收尾相连形成循环链表,这个queue作为哨兵节点,当有新的节点插入时就插入到queue的前面,相当于在整个链表的最后插入元素。该链表节点的关键结构如下:
1 | |
_next 和 _prev表示节点的向前引用和向后引用,其使用atomic包裹仅能进行原子操作。不过CAS操作通常只能修改一个引用,对于需要同时修改前后节点引用的情形是不适用的。当我们在单链表中插入节点时,也会存在并发问题,如下图所示。
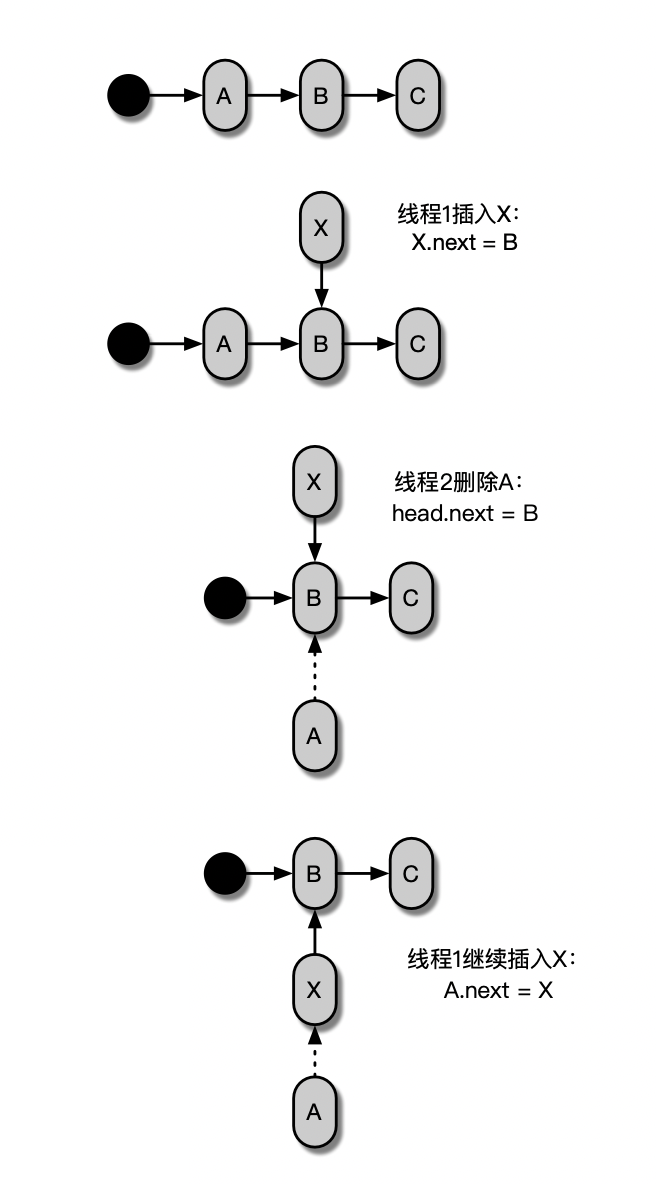
而无锁链表LockFreeLinked的实现是引入一个prev来辅助完成。A被移除时不会像单链表一样直接断开指针, 而是现将A.next和A.prev标记为Removed,指向的节点不变,因此即便同时有另一个线程插入一个节点X,链表同样有机会在后续通过CAS算法实现前后节点引用的修复。具体实现参照LockFreeLinkedListNode在JVM上的实现。
而对于数组版本,ArrayChannel相对就比较简单了,其内部维护了一个数组:
1 | |
对这个数组的读写操作都会使用可重入锁ReentrantLock进行加锁。
冷数据流Flow
我们现在大多数App都使用了RxJava作为异步框架,而RxJava的核心就是响应式编程模型。Flow就是Kotlin协程与响应式编程模型结合的产物。
认识Flow
先来使用flow创建发送序列,这里对比一下官方的序列生成器sequence:
1 | |
我们知道,sequence不支持传入协程上下文,因而无法对协程进行线程调度。而受SequenceScope的RestrictsSuspension注解的影响,其内部也无法调用外部的的挂起函数。这其中其实是有个因果关系的,假设sequence支持调用delay,由于sequence本身不支持调度,所以会导致delay执行后会有切换线程的副作用。而Flow则没有这么多限制了,我们可以内部使用emit发送元素,可调用外部的挂起函数,同时也可以使用flowOn函数进行线程调度。
Flow的线程切换
Flow的线程切换使用Flow.flowOn方法,这个方法与RxJava的subscribeOn和observeOn切换协程的方式十分类似,下面是对比代码。
1 | |
可以看到flowOn方法与RxJava的subscribeOn方法十分类似,都是会只会影响其之前的代码,而且都是只有第一次调用是有效的,这个其实跟collect或者subscribe的逆序调用执行有关,代码顺序中第一次调用flowOn或者subscribeOn其实是最后才执行,所以它们是有效的,这里不深究了。另外区别是RxJava中可以使用observeOn方法来调度subscribe回调的执行线程,看起来似乎Flow的collect没有类似的调度方法,其实不然,Flow的collect是个挂起函数,其调度线程跟外部的协程调度在哪个线程是一致的。
冷数据流
与RxJava类似,Flow的生产总是在消费被调用后才会执行,并且多次调用会多次生产。
1 | |
所谓的冷数据流,就是只有消费时才会生产的数据流,这一点与Channel刚好相反。
异常处理
Flow异常处理比较简单直接,直接调用catch函数即可。
1 | |
我们使用catch函数捕获flow中抛出的异常,这里需要注意的是catch只能捕获上游的异常,如果没有catch,则会在消费时抛出。
onCompletion方法的作用类似于RxJava中Subscriber的OnComplete,作为整个Flow完成的回调使用,无论是否存在未捕获的异常都会被调用。
末端操作符
前面我们使用了collect来消费Flow的数据,像这种包含消费含义的操作符称为末端操作符。Flow的末端操作符大体可以分为两类:
- 集合类型转换操作符,包括toList、toSet等。
- 聚合操作符,包括将Flow规约到单值的reduce、fold等操作;还有获得单个元素的操作符,包括single、singleOrNull、first等。
分离Flow的消费和触发
我们除了可以在collect处消费Flow的元素之外,还可以通过onEach来消费元素,而collect只需要作为触发点就可以。
1 | |
另外Flow中还提供了一个launchIn方法指定一个协程作用域,使其消费在指定的协程中。
1 | |
Flow的取消
Flow不存在取消的概念,因为其依托于外部协程的生命周期,所以要想取消一个Flow只需要取消其外部协程即可。
其他Flow的创建方式
之前我们使用了flow{…}来创建一个Flow,这种方式的缺点是当中无法随意切换调度器,如果在当中使用调度器会报错,因为emit函数不是线程安全的。如果需要在生成元素时切换调度器可以使用ChannelFlow,通过channelFlow{…}来创建。
Flow的背压
只要是响应式编程就会有背压问题,即生产者生产元素的速率远高于消费者的处理速率时,消费者还未处理上一个数据新数据就已经到达的情况。
为了保证数据不丢失,我们可以为Flow添加缓冲区。
1 | |
不过如果只是单纯添加缓冲,缓冲区迟早也会出现数据积压,只是治标不治本。
要从根本上解决背压问题,除了直接优化消费者的性能外,还可以采用一些取舍手段。
第一种是conflate。与Channel中的Conflate模式一直,新数据会覆盖老数据,使用方法如下所示。
1 | |
上述代码快速发送了100个元素,最后接收到的只有2个。
第二种是collectLasted,作用是只处理最新的数据。看起来似乎与conflate是一样的,其实不然,collectLasted不会进行数据的覆盖,而是在当前数据还未处理完而新的数据来的时候,当前数据的处理逻辑会被取消,转而处理新数据。
除了collectLasted之外,还有mapLastest、flatMapLatest等。
Flow的变换
Flow与RxJava的Observable一样,可以使用map、flattenConcat等函数来进行变换。
select表达式
select在Java NIO里很常见,Kotlin协程中的select用于同时等待多个挂起函数,并可以选择第一个恢复的gaug挂起。
复用多个await
假设我们有个常见是分别从本地和网络获取数据,哪个先返回就用哪个,那么如何做到这一点呢?
1 | |
我们可以使用select来同时启动这两个挂起函数,并最终返回先恢复的那个挂起函数返回的数据,如下:
1 | |
我们没有直接调用await,而是使用Deferred#onAwait方法在select中注册了回调,select总是会立即调用最先返回的事件的回调。
复用多个Channel
对于多个Channel的情况,也比较类似:
1 | |
对于 onReceive,如果Channel被关闭,select会直接抛出异常;而对于 onReceiveOrNull如果遇到Channel被关闭的情况,it的值就是null。
SelectClause
如何知道哪些事件可以被select呢?实际上所有能够被select的事件都是SelectClauseN类型,包括:
SelectClause0:对应事件没有返回值,例如join没有返回值,那么onJoin就是SelectClauseN类型。使用时,onJoin的参数是一个无惨函数。
1
2
3select<Unit> {
job.onJoin { println("Join resumed!") }
}SelectClause1:对应事件有返回值,前面的onAwait和onReceive都是此类情况。
SelectClause2:对应事件有返回值,此外还需要一个额外的参数作为回调,例如Channel.onSend有两个参数,第一个表示即将发送的值,第二个是发送成功的回调。
1
2
3
4
5
6
7
8
9List(100) { element ->
select<Unit> {
channels.forEach { channel ->
channel.onSend(element) { sentChannel ->
println("send on $sentChannel")
}
}
}
}
综上,如果想要确认挂起函数是否支持select,只需要查看其是否存在对应的SelectClauseN类型可回调即可。
使用Flow实现多路复用
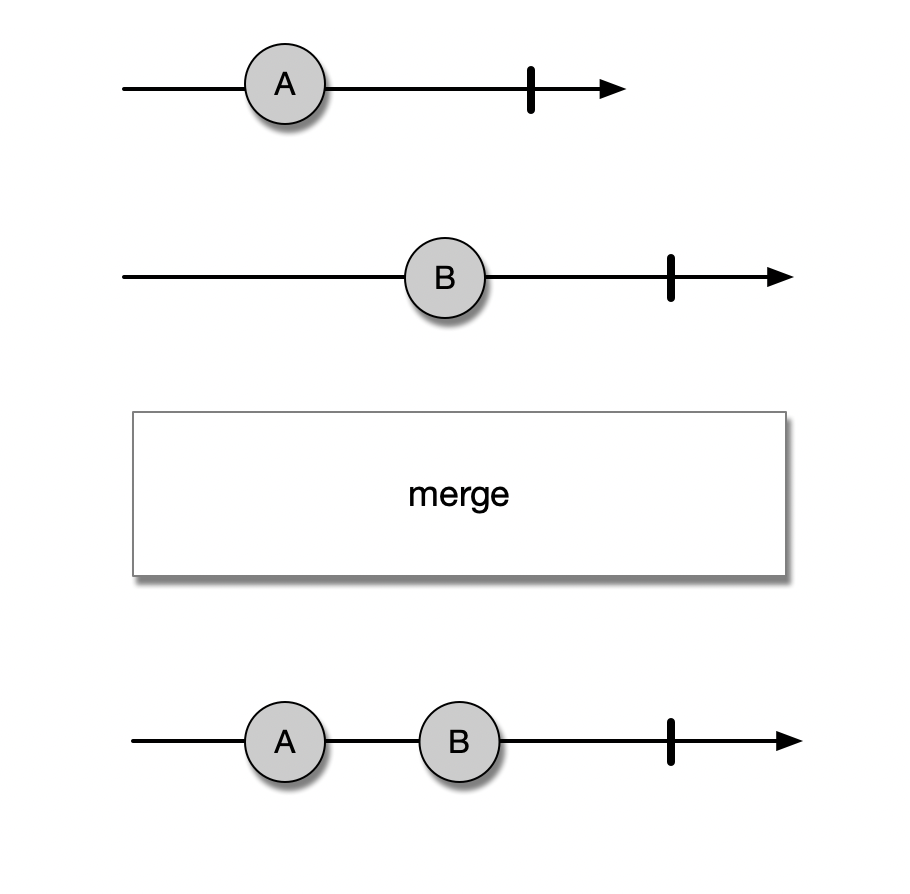
多数情况下,我们可以通过构造何时的Flow来实现多路复用的效果。
1 | |
上面代码的关键之处在于,我们为每一个deferred都创建了一个单独的Flow,并在Flow内部发送了deferred.await()返回的结果,最后再通过merge函数合并成一个Flow来进行处理。
协程的并发工具
协程框架提供了一些并发安全的工具,包括:
Channel:并发安全的消息通道。
Mutex:轻量级锁,在获取不到锁时不会阻塞线程而是挂起等待锁的释放。代码如下所示。
1
2
3
4
5
6
7
8
9var count = 0
val mutex = Mutex()
List(1000) {
GlobalScope.launch {
mutex.withLock {
count++
}
}
}.joinAll()Semaphore:轻量级信号量,信号量可以有多个,协程在获取到信号量后即可执行并发操作。当Semaphore的参数为1时,效果等价于Mutex,代码示例如下。
1
2
3
4
5
6
7
8
9var count = 0
val semaphore = Semaphore(1)
List(1000) {
GlobalScope.launch {
semaphore.withPermit {
count++
}
}
}.joinAll()
参考
- Kotlin标准库1.4.21 ↩
- 《深入理解Kotlin协程》 ↩